diff --git a/KVM企业面试题.md b/KVM企业面试题.md
new file mode 100644
index 0000000..1585952
--- /dev/null
+++ b/KVM企业面试题.md
@@ -0,0 +1,49 @@
+KVM企业面试题
+
+作者:行癫(盗版必究)
+
+------
+
+1.什么是KVM?
+
+答:KVM是一种基于Linux内核的开源虚拟化技术,它允许在一个物理主机上运行多个虚拟机实例,并提供硬件级别的虚拟化支持。
+
+2.KVM的工作原理是什么?
+
+答:KVM利用处理器的虚拟化扩展(如Intel VT、AMD-V)来创建虚拟化环境。它通过将Linux内核转变为虚拟化管理程序来实现,在此之上运行虚拟机作为客户机。
+
+3.KVM和QEMU之间的关系是什么?
+
+答:KVM依赖于QEMU(Quick Emulator)来模拟物理硬件并提供I/O设备模拟。QEMU实际上执行虚拟机的模拟,而KVM负责提供处理器虚拟化支持。
+
+4.KVM支持哪些虚拟化架构?
+
+答:KVM支持基于硬件的虚拟化扩展,如Intel的VT-x和AMD的AMD-V,这些扩展允许KVM在处理器级别实现虚拟化。
+
+5.如何管理KVM虚拟化环境?
+
+答:KVM管理可以通过命令行工具如virsh,图形化工具如virt-manager,以及其他管理工具和API进行。这些工具允许管理员创建、配置、监视和控制KVM虚拟机。
+
+6.KVM的优化和性能调优策略是什么?
+
+答:优化KVM性能的策略包括使用虚拟化扩展、合理配置虚拟机的资源(CPU、内存、磁盘、网络)、选择适当的调度器、以及使用I/O虚拟化等技术来提高效率和性能。
+
+7.KVM在云计算中的应用和优势是什么?
+
+答:KVM作为一种轻量级、高性能的虚拟化技术,被广泛应用于云计算基础设施中。它提供了良好的隔离性、高性能、灵活性和可扩展性,使得在云环境中部署和管理虚拟机变得更加简便和有效。
+
+8.KVM安全性方面的问题和解决方案是什么?
+
+答:KVM安全性涉及控制对宿主机和虚拟机的访问、网络安全、更新维护、对虚拟机间的隔离等方面。加强虚拟机和宿主机的安全性需要采取安全补丁、访问控制、网络隔离等措施。
+
+9.KVM如何管理虚拟机迁移中的网络状态?
+
+答:在虚拟机迁移过程中,KVM会利用Live Migration技术维持虚拟机的网络连通性,保证迁移过程中网络不中断。
+
+19.KVM如何实现虚拟机之间的网络隔离?
+
+答:KVM通过网络桥接、VLAN或者虚拟交换机等机制来实现虚拟机间的网络隔离,确保不同虚拟机之间的通信可以被隔离和控制。
+
+11.KVM中的IO虚拟化是如何工作的?
+
+答:KVM使用virtio来实现IO虚拟化,它是一种通用的虚拟化IO设备的框架,使得虚拟机能够与宿主机的IO设备进行高效的通信。
\ No newline at end of file
diff --git a/Logstash-过滤.md b/Logstash-过滤.md
new file mode 100644
index 0000000..5441a67
--- /dev/null
+++ b/Logstash-过滤.md
@@ -0,0 +1,56 @@
+LogStash 数据过滤
+
+作者:行癫(盗版必究)
+
+------
+
+## 一:grok插件
+
+#### 1.简介
+
+ grok插件有非常强大的功能,他能匹配一切数据,但是他的性能和对资源的损耗同样让人诟病
+
+ filter的grok是目前logstash中解析非结构化日志数据最好的方式
+
+ grok位于正则表达式之上,所以任何正则表达式在grok中都是有效的
+
+#### 2.语法格式
+
+```shell
+%{语法:语义}
+```
+
+注意:
+
+ 语法指的是匹配的模式
+
+ 例如使用NUMBER模式可以匹配出数字,IP模式则会匹配出127.0.0.1这样的IP地址
+
+#### 3.案例
+
+实验数据:Nginx的访问日志
+
+Logstash输入输出配置文件:
+
+```shell
+input {
+ stdin {
+ }
+}
+filter{
+ grok{
+ match => {"message" => "%{IP:client}"}
+ }
+}
+output {
+ stdout {
+ }
+}
+```
+
+
+
+
+
+
+
diff --git a/互联网公司架构规模.md b/互联网公司架构规模.md
new file mode 100644
index 0000000..3d542e2
--- /dev/null
+++ b/互联网公司架构规模.md
@@ -0,0 +1,38 @@
+互联网公司架构规模
+
+作者:行癫(盗版必究)
+
+------
+
+小型互联网公司的IT架构规模会因公司的具体需求和业务模式而有所不同,但通常包括以下基本组件和规模:
+
+1. **硬件基础设施**:
+ - 服务器:小型公司可能会使用数台物理服务器或虚拟机来托管其应用程序和数据库。
+ - 存储:通常采用网络附加存储(NAS)或云存储服务,以存储数据和备份。
+ - 网络设备:包括路由器、交换机和防火墙,以确保网络的稳定性和安全性。
+2. **云服务**:
+ - 很多小型公司选择采用云计算服务(如AWS、Azure、Google Cloud)来托管应用程序和存储数据,这样可以减少硬件成本和提高可伸缩性。
+3. **操作系统和虚拟化**:
+ - 服务器通常运行Linux或Windows操作系统,并可能使用虚拟化技术(如VMware或Docker)来隔离应用程序和服务。
+4. **应用程序**:
+ - Web应用程序:用于公司的在线业务,如网站、电子商务平台等。
+ - 数据库:通常会使用关系型数据库(如MySQL、PostgreSQL)或NoSQL数据库(如MongoDB)来存储数据。
+ - 通信工具:如电子邮件服务器、即时消息应用程序等。
+ - 协作工具:如文档管理、项目管理、团队聊天工具等。
+5. **安全性**:
+ - 防火墙和入侵检测系统(IDS):用于保护公司的网络和数据。
+ - 访问控制:确保只有授权用户能够访问敏感数据和系统。
+6. **监控和日志**:
+ - 监控工具:如Prometheus、Grafana等,用于实时监控系统性能和健康。
+ - 日志管理:用于记录应用程序和系统事件,如Elasticsearch和Logstash。
+7. **备份和灾难恢复**:
+ - 定期备份数据,以确保在数据丢失或硬件故障时能够快速恢复。
+ - 制定灾难恢复计划,以准备面对更严重的系统中断。
+8. **网络拓扑**:
+ - 常见的网络拓扑包括单层或多层架构,以确保网络流量的流畅和安全。
+9. **可伸缩性**:
+ - IT架构应具备可伸缩性,以应对业务增长。这可能包括负载均衡器和自动扩展机制。
+10. **成本控制**:
+ - 确保IT支出在公司的预算范围内,并考虑采用开源软件或云计算服务来减少成本。
+
+需要强调的是,每家公司的IT架构都会根据业务需求和预算来定制,所以在规划和实施IT架构时,需要综合考虑多个因素。随着公司的发展,IT架构可能需要不断优化和升级。
\ No newline at end of file
diff --git a/日志中心集群.md b/日志中心集群.md
index 62c77c9..e5a1c83 100644
--- a/日志中心集群.md
+++ b/日志中心集群.md
@@ -232,881 +232,4 @@ http.cors.allow-origin 允许的源地址。
-
-
-## 三:Kibana安装部署
-
-#### 1.获取包
-
- 无
-
-#### 2.解压安装
-
-```shell
-[root@kibana ~]# tar xf kibana-6.5.4-linux-x86_64.tar.gz
-[root@kibana ~]# mv kibana-6.5.4-linux-x86_64 /usr/local/kibana
-```
-
-#### 3.修改配置
-
-```shell
-[root@kibana ~]# vi /usr/local/kibana/config/kibana.yml
-server.port: 5601
-server.host: "172.16.244.28"
-elasticsearch.url: "http://172.16.244.25:9200"
-kibana.index: ".kibana"
-```
-
-注意:
-
- server.port kibana服务端口,默认5601
-
- server.host kibana主机IP地址,默认localhost
-
- elasticsearch.url 用来做查询的ES节点的URL,默认http://localhost:9200
-
-#### 4.启动访问
-
-```sjell
-[root@kibana ~]# cd /usr/local/kibana
-nohup ./bin/kibana &
-```
-
-5.使用kibana关联到ES
-
-
-
-## 四:Logstash安装部署
-
-#### 1.获取包
-
- 无
-
-#### 2.解压安装
-
-```shell
-[root@logstash ~]# tar zxvf /usr/local/package/jdk-8u121-linux-x64.tar.gz -C /usr/local/
-[root@logstash ~]# mv /usr/local/jdk-8u121 /usr/local/java
-[root@logstash ~]# vim /etc/profile
-JAVA_HOME=/usr/local/java
-PATH=$JAVA_HOME/bin:$PATH
-export JAVA_HOME PATH
-[root@logstash ~]# source /etc/profile
-[root@logstash ~]# tar xf logstash-6.5.0.tar.gz -C /opt/
-[root@logstash ~]# mv /opt/logstash-6.5.0/ /opt/logstash
-```
-
-#### 3.使用
-
-输入输出都为终端
-
-```shell
-[root@elk-node1 ~]# /opt/logstash/bin/logstash -e 'input { stdin{} } output { stdout{} }'
--e 后面跟搜集定义输出(input [filter] output)后面跟{}
-```
-
-输入是终端的标准输入,输出到ES集群
-
-```shell
-[root@elk-node1 ~]# /opt/logstash/bin/logstash -e 'input { stdin{} } output { elasticsearch { hosts => ["192.168.1.160:9200"]} }'
-Settings: Default filter workers: 1
-Logstash startup completed #输入下面的测试数据
-123456
-wangshibo
-huanqiu
-hahaha
-```
-
-采集单个文件
-
-```json
-[root@logstash ~]# cat /opt/nginx_access_logstash.conf
-input{
- file {
- path => "/var/log/nginx/access_json.log"
- start_position => "beginning"
- }
-}
-
-output{
-
- elasticsearch {
- hosts => ["10.9.12.86:9200"]
- index => "nginx-access-json-%{+YYYY.MM.dd}"
- }
-
-}
-```
-
-采集多个文件
-
-```json
-[root@logstash ~]# cat /opt/files.conf
-input {
- file {
- path => "/var/log/messages"
- type => "system"
- start_position => "beginning"
- }
-}
-input {
- file {
- path => "/var/log/yum.log"
- type => "safeware"
- start_position => "beginning"
- }
-}
-output {
-
- if [type] == "system"{
- elasticsearch {
- hosts => ["10.9.12.86:9200"]
- index => "system-%{+YYYY.MM.dd}"
- }
- }
- if [type] == "safeware"{
- elasticsearch {
- hosts => ["10.9.12.86:9200"]
- index => "safeware-%{+YYYY.MM.dd}"
- }
- }
-}
-```
-
-#### 4.定义nginx的日志格式并采集
-
-Nginx配置文件修改
-
-```
- log_format json '{"@timestamp":"$time_iso8601",'
- '"@version":"1",'
- '"client":"$remote_addr",'
- '"url":"$uri",'
- '"status":"$status",'
- '"domain":"$host",'
- '"host":"$server_addr",'
- '"size":$body_bytes_sent,'
- '"responsetime":$request_time,'
- '"referer": "$http_referer",'
- '"ua": "$http_user_agent"'
- '}';
-
-
- access_log /var/log/nginx/access_json.log json;
-```
-
-定义采集配置文件
-
-```json
-input {
- file {
- path => "/var/log/nginx/access_json.log"
- start_position => "beginning"
- }
-}
-output {
- elasticsearch {
- hosts => ["192.168.122.118:9200"]
- index => "nginx1-%{+YYYY.MM.dd}"
- }
-}
-```
-
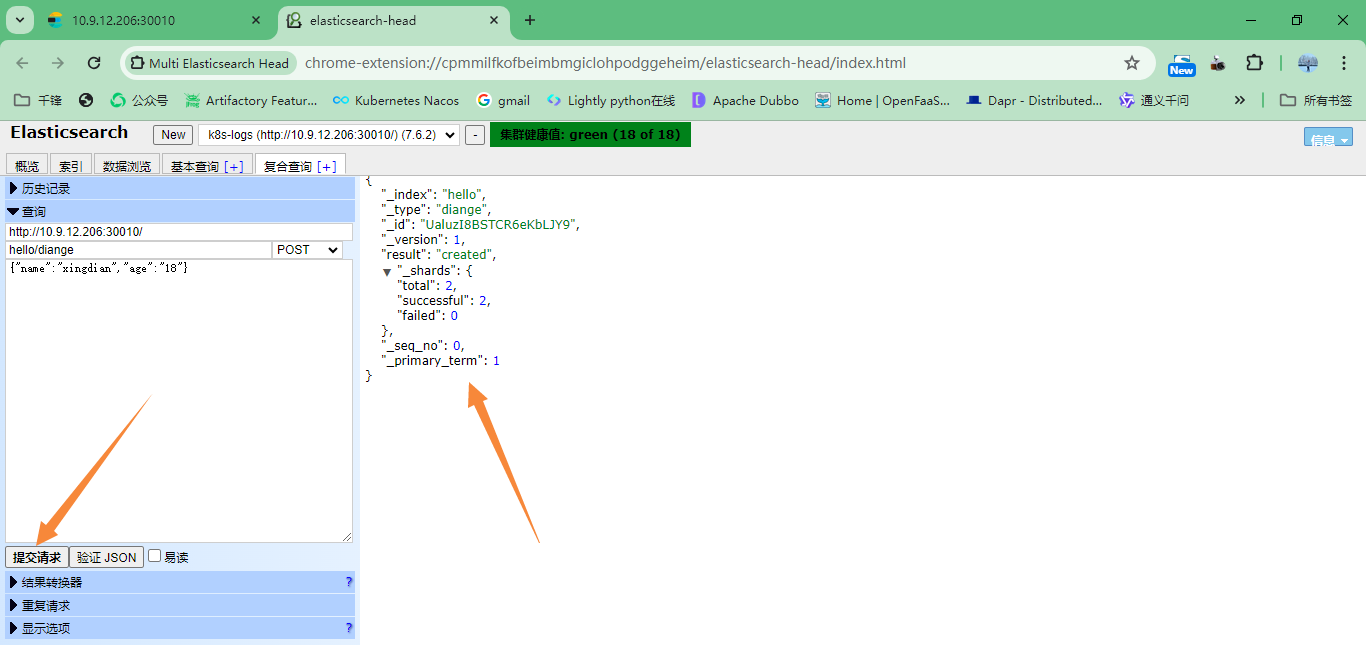
-ES查看索引,Kibana展示数据
-
-## 五:Kakfa
-
-#### 1.理论
-
-```shell
-kafka是一个分布式的消息发布—订阅系统(kafka其实是消息队列)
-http://kafka.apache.org/
-
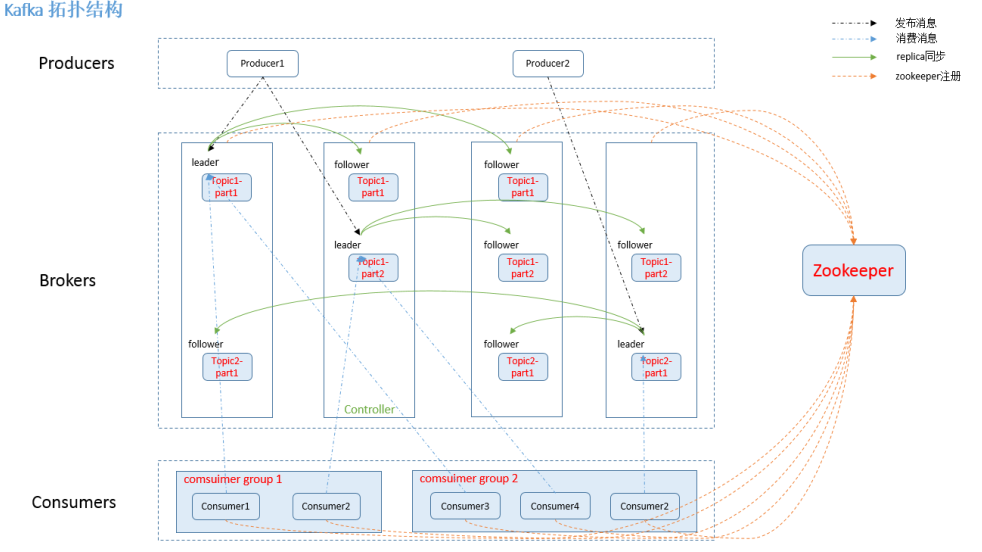
- Kafka是最初由Linkedin公司开发,是一个分布式、支持分区的(partition)、多副本的(replica),基于zookeeper协调的分布式消息系统,它的最大的特性就是可以实时的处理大量数据以满足各种需求场景:比如基于hadoop的批处理系统、低延迟的实时系统、storm/Spark流式处理引擎,web/nginx日志、访问日志,消息服务等等,用scala语言编写,Linkedin于2010年贡献给了Apache基金会并成为顶级开源 项目。
-
-Kafka的特性:
-- 高吞吐量、低延迟:kafka每秒可以处理几十万条消息,它的延迟最低只有几毫秒,每个topic可以分多个partition, consumer group 对partition进行consumer操作。
-- 可扩展性:kafka集群支持热扩展
-- 可靠性:消息被持久化到本地磁盘,并且支持数据备份防止数据丢失
-- 容错性:允许集群中节点失败(若副本数量为n,则允许n-1个节点失败)
-- 高并发:支持数千个客户端同时读写
-kafka组件:
-话题(Topic):是特定类型的消息流。消息是字节的有效负载(Payload),话题是消息的分类名或种子(Feed)名。(每条发布到 kafka 集群的消息属于的类别,即 kafka 是面向 topic 的)。
-生产者(Producer):是能够发布消息到话题的任何对象(发布消息到 kafka 集群的终端或服务).
-服务代理(Broker):已发布的消息保存在一组服务器中,它们被称为代理(Broker)或Kafka集群。
-消费者(Consumer):可以订阅一个或多个话题,并从Broker拉数据,从而消费这些已发布的消息。
-partition(区):partition 是物理上的概念,每个 topic 包含一个或多个 partition。每一个topic将被分为多个partition(区)。
-Consumer group:high-level consumer API 中,每个 consumer 都属于一个 consumer group,每条消息只能被 consumer group 中的一个 Consumer 消费,但可以被多个 consumer group 消费。
-replication:partition 的副本,保障 partition 的高可用。
-leader:replication 中的一个角色, producer 和 consumer 只跟 leader 交互。
-follower:replication 中的一个角色,从 leader 中复制数据。
-controller:kafka 集群中的其中一个服务器,用来进行 leader election 以及 各种 failover。
-zookeeper:kafka 通过 zookeeper 来存储集群的 meta 信息。
-```
-
-
-
-#### 2.部署
-
-```shell
-Kafka部署(所有节点都部署)
-1.安装jdk
-[root@xingdian ~]# tar zxvf /usr/local/package/jdk-8u121-linux-x64.tar.gz -C /usr/local/
-[root@xingdian ~]# mv /usr/local/jdk-8u121 /usr/local/java
-[root@xingdian ~]# vim /etc/profile
-JAVA_HOME=/usr/local/java
-PATH=$JAVA_HOME/bin:$PATH
-export JAVA_HOME PATH
-[root@xingdian ~]# source /etc/profile
-
-2.安装ZK
-Kafka运行依赖ZK,Kafka官网提供的tar包中,已经包含了ZK,这里不再额下载ZK程序。
-tar zxvf /usr/local/package/kafka_2.11-2.1.0.tgz -C /usr/local/
-3.配置
-sed -i 's/^[^#]/#&/' /usr/local/kafka_2.11-2.1.0/config/zookeeper.properties
-vi /usr/local/kafka/config/zookeeper.properties
- dataDir=/opt/data/zookeeper/data
- dataLogDir=/opt/data/zookeeper/logs
- clientPort=2181
- tickTime=2000
- initLimit=20
- syncLimit=10
- server.1=172.16.244.31:2888:3888 //kafka集群IP:Port
- server.2=172.16.244.32:2888:3888
- server.3=172.16.244.33:2888:3888
-#创建data、log目录
-mkdir -p /opt/data/zookeeper/{data,logs}
-#创建myid文件
-echo 1 > /opt/data/zookeeper/data/myid
-注意:
-dataDir ZK数据存放目录。
-dataLogDir ZK日志存放目录。
-clientPort 客户端连接ZK服务的端口。
-tickTime ZK服务器之间或客户端与服务器之间维持心跳的时间间隔。
-initLimit 允许follower(相对于Leaderer言的“客户端”)连接并同步到Leader的初始化连接时间,以tickTime为单位。当初始化连接时间超过该值,则表示连接失败。
-syncLimit Leader与Follower之间发送消息时,请求和应答时间长度。如果follower在设置时间内不能与leader通信,那么此follower将会被丢弃。
-server.1=172.16.244.31:2888:3888 2888是follower与leader交换信息的端口,3888是当leader挂了时用来执行选举时服务器相互通信的端口。
-
-4.配置kafka
-sed -i 's/^[^#]/#&/' /usr/local/kafka/config/server.properties
-vi /usr/local/kafka/config/server.properties
-broker.id=1
-listeners=PLAINTEXT://172.16.244.31:9092
-num.network.threads=3
-num.io.threads=8
-socket.send.buffer.bytes=102400
-socket.receive.buffer.bytes=102400
-socket.request.max.bytes=104857600
-log.dirs=/opt/data/kafka/logs
-num.partitions=6
-num.recovery.threads.per.data.dir=1
-offsets.topic.replication.factor=2
-transaction.state.log.replication.factor=1
-transaction.state.log.min.isr=1
-log.retention.hours=168
-log.segment.bytes=536870912
-log.retention.check.interval.ms=300000
-zookeeper.connect=172.16.244.31:2181,172.16.244.32:2181,172.16.244.33:2181
-zookeeper.connection.timeout.ms=6000
-group.initial.rebalance.delay.ms=0
-#创建log目录 mkdir -p /opt/data/kafka/logs
-注意:
-broker.id 每个server需要单独配置broker id,如果不配置系统会自动配置。
-listeners 监听地址,格式PLAINTEXT://IP:端口。
-num.network.threads 接收和发送网络信息的线程数。
-num.io.threads 服务器用于处理请求的线程数,其中可能包括磁盘I/O。
-socket.send.buffer.bytes 套接字服务器使用的发送缓冲区(SO_SNDBUF)
-socket.receive.buffer.bytes 套接字服务器使用的接收缓冲区(SO_RCVBUF)
-socket.request.max.bytes 套接字服务器将接受的请求的最大大小(防止OOM)
-log.dirs 日志文件目录。
-num.partitions partition数量。
-num.recovery.threads.per.data.dir 在启动时恢复日志、关闭时刷盘日志每个数据目录的线程的数量,默认1。
-offsets.topic.replication.factor 偏移量话题的复制因子(设置更高保证可用),为了保证有效的复制,偏移话题的复制因子是可配置的,在偏移话题的第一次请求的时候可用的broker的数量至少为复制因子的大小,否则要么话题创建失败,要么复制因子取可用broker的数量和配置复制因子的最小值。
-log.retention.hours 日志文件删除之前保留的时间(单位小时),默认168
-log.segment.bytes 单个日志文件的大小,默认1073741824
-log.retention.check.interval.ms 检查日志段以查看是否可以根据保留策略删除它们的时间间隔。
-zookeeper.connect ZK主机地址,如果zookeeper是集群则以逗号隔开。
-zookeeper.connection.timeout.ms 连接到Zookeeper的超时时间。
-
-5.其他配置节点配置相同(myid,broker.id 不同)
-
-6.启动验证zk集群
-三个节点依次执行:
-cd /usr/local/kafka
-nohup bin/zookeeper-server-start.sh config/zookeeper.properties &
-
-7.验证
-#echo conf | nc 127.0.0.1 2181
-clientPort=2181
-dataDir=/data/zookeeper/data/version-2
-dataLogDir=/data/zookeeper/logs/version-2
-tickTime=2000
-maxClientCnxns=60
-minSessionTimeout=4000
-maxSessionTimeout=40000
-serverId=1
-initLimit=20
-syncLimit=10
-electionAlg=3
-electionPort=3888
-quorumPort=2888
-peerType=0
-
-#echo stat | nc 127.0.0.1 2181
-Zookeeper version: 3.4.13-2d71af4dbe22557fda74f9a9b4309b15a7487f03, built on 06/29/2018 00:39 GMT
-Clients:
- /172.17.0.4:35020[0](queued=0,recved=1,sent=0)
-
-Latency min/avg/max: 0/0/0
-Received: 4
-Sent: 3
-Connections: 1
-Outstanding: 0
-Zxid: 0x0
-Mode: follower
-Node count: 4
-
-8.查看端口
- lsof -i:2181
-COMMAND PID USER FD TYPE DEVICE SIZE/OFF NODE NAME
-java 2442 root 92u IPv4 1031572 0t0 TCP *:eforward (LISTEN)
-
-9.启动、验证Kafka(三个节点依次启动)
-cd /usr/local/kafka_2.11-2.1.0/
-nohup bin/kafka-server-start.sh config/server.properties &
-验证:
-创建topic
-# bin/kafka-topics.sh --create --zookeeper 172.17.0.4:2181 --replication-factor 1 --partitions 1 --topic testtopic
-Created topic "testtopic".
-查询topic
-# bin/kafka-topics.sh --zookeeper 172.17.0.4:2181 --list
-testtopic
-模拟消息生产和消费 发送消息到172.17.0.4
-bin/kafka-console-producer.sh --broker-list 172.17.0.4:9092 --topic testtopic
->Hello World!
-从172.16.244.32接受消息
-# bin/kafka-console-consumer.sh --bootstrap-server 172.17.0.4:9092 --topic testtopic --from-beginning
-Hello World!
-查看主题的信息:
-./bin/kafka-topics.sh --describe --zookeeper 172.17.0.4:2181 --topic testtopic
-
-
-```
-
-## 六:Filebeat
-
-#### 1.理论
-
-```
- Filebeat是本地文件的日志数据采集器。 作为服务器上的代理安装,Filebeat监视日志目录或特定日志文件,并将它们转发给Elasticsearch或Logstash进行索引、kafka 等。
-
-
-工作原理:
- Filebeat由两个主要组件组成:prospector 和harvester。这些组件一起工作来读取文件并将事件数据发送到您指定的输出。
-
- 启动Filebeat时,它会启动一个或多个查找器,查看您为日志文件指定的本地路径。 对于prospector 所在的每个日志文件,prospector 启动harvester。 每个harvester都会为新内容读取单个日志文件,并将新日志数据发送到libbeat,后者将聚合事件并将聚合数据发送到您为Filebeat配置的输出。
- harvester :负责读取单个文件的内容。读取每个文件,并将内容发送到 the output每个文件启动一harvester, harvester 负责打开和关闭文件,这意味着在运行时文件描述符保持打开状态,如果文件在读取时被删除,Filebeat将继续读取文件。
- prospector 负责管理harvester并找到所有要读取的文件来源。如果输入类型为日志,则查找器将查找路径匹配的所有文件,并为每个文件启动一个harvester。每个prospector都在自己的Go协程中运行。
-
-
-注意:
- Filebeat目前支持两种prospector类型:log和stdin。
- 每个prospector类型可以定义多次。
- 日志prospector检查每个文件以查看harvester是否需要启动,是否已经运行,或者该文件是否可以被忽略。
- Filebeat prospector只能读取本地文件, 没有功能可以连接到远程主机来读取存储的文件或日志。
-
-Filebeat如何确保至少一次交付?
-
- Filebeat保证事件至少会被传送到配置的输出一次,并且不会丢失数据。 Filebeat能够实现此行为,因为它将每个事件的传递状态存储在注册文件中。在输出阻塞或未确认所有事件的情况下,Filebeat将继续尝试发送事件,直到接收端确认已收到。
- 如果Filebeat在发送事件的过程中关闭,它不会等待输出确认所有收到事件。
- 发送到输出但在Filebeat关闭前未确认的任何事件在重新启动Filebeat时会再次发送。
- 这可以确保每个事件至少发送一次,但最终会将重复事件发送到输出。
- 也可以通过设置shutdown_timeout选项来配置Filebeat以在关闭之前等待特定时间。
-
-为什么使用filebeat?
-
- Filebeat是一种轻量级的日志搜集器,其不占用系统资源,自出现之后,迅速更新了原有的elk架构。Filebeats将收集到的数据发送给Logstash解析过滤,在Filebeats与Logstash传输数据的过程中,为了安全性,可以通过ssl认证来加强安全性。之后将其发送到Elasticsearch存储,并由kibana可视化分析。
-
-```
-
-
-
-#### 2.启动参数
-
-```
--c, --c FILE
- 指定用于Filebeat的配置文件。 你在这里指定的文件是相对于path.config。 如果未指定-c标志,则使用默认配置文件filebeat.yml。
--d, --d SELECTORS
- 启用对指定选择器的调试。 对于选择器,可以指定逗号分隔的组件列表,也可以使用-d“*”为所有组件启用调试。 例如,-d “publish”显示所有“publish”相关的消息。
--e, --e
- 记录到stderr并禁用syslog /文件输出。
--v, --v
- 记录INFO级别的消息。
-
-1.测试filebeat启动后,查看相关输出信息:
-./filebeat -e -c filebeat.yml -d "publish"
-
-2.后台方式启动filebeat:
-nohup ./filebeat -e -c filebeat.yml >/dev/null 2>&1 &
- 将所有标准输出及标准错误输出到/dev/null空设备,即没有任何输出
-nohup ./filebeat -e -c filebeat.yml > filebeat.log &
-
-nohup ./filebeat -c filebeat.yml &
-
-3.停止filebeat:
-
-ps -ef |grep filebeat | kill -9 进程号
-```
-
-#### 3.配置参数
-
-```shell
-############### Filebeat 配置文件说明#############
-filebeat:
- # List of prospectors to fetch data.
- prospectors:
- -
- # paths指定要监控的日志
- paths:
- - /var/log/*.log
-
- #指定被监控的文件的编码类型使用plain和utf-8都是可以处理中文日志的。
- # Some sample encodings:
- # plain, utf-8, utf-16be-bom, utf-16be, utf-16le, big5, gb18030, gbk,
- # hz-gb-2312, euc-kr, euc-jp, iso-2022-jp, shift-jis, ...
- #encoding: plain
-
- #指定文件的输入类型log(默认)或者stdin。
- input_type: log
-
- # 在输入中排除符合正则表达式列表的那些行
- # exclude_lines: ["^DBG"]
-
- # 包含输入中符合正则表达式列表的那些行默认包含所有行include_lines执行完毕之后会执行exclude_lines。
- # include_lines: ["^ERR", "^WARN"]
-
- # 忽略掉符合正则表达式列表的文件默认为每一个符合paths定义的文件都创建一个harvester。
- # exclude_files: [".gz$"]
-
- # 向输出的每一条日志添加额外的信息比如“level:debug”方便后续对日志进行分组统计。默认情况下会在输出信息的fields子目录下以指定的新增fields建立子目录例如fields.level。
- #fields:
- # level: debug
- # review: 1
-
- # 如果该选项设置为true则新增fields成为顶级目录而不是将其放在fields目录下。自定义的field会覆盖filebeat默认的field。
- #fields_under_root: false
-
- # 可以指定Filebeat忽略指定时间段以外修改的日志内容比如2h两个小时或者5m(5分钟)。
- #ignore_older: 0
-
- # 如果一个文件在某个时间段内没有发生过更新则关闭监控的文件handle。默认1h,change只会在下一次scan才会被发现
- #close_older: 1h
-
- # 设定Elasticsearch输出时的document的type字段也可以用来给日志进行分类。Default: log
- #document_type: log
-
- # Filebeat以多快的频率去prospector指定的目录下面检测文件更新比如是否有新增文件如果设置为0s则Filebeat会尽可能快地感知更新占用的CPU会变高。默认是10s。
- #scan_frequency: 10s
-
- # 每个harvester监控文件时使用的buffer的大小。
- #harvester_buffer_size: 16384
-
- # 日志文件中增加一行算一个日志事件max_bytes限制在一次日志事件中最多上传的字节数多出的字节会被丢弃。The default is 10MB.
- #max_bytes: 10485760
-
- # 适用于日志中每一条日志占据多行的情况比如各种语言的报错信息调用栈。这个配置的下面包含如下配置
- #multiline:
-
- # The regexp Pattern that has to be matched. The example pattern matches all lines starting with [
- #pattern: ^\[
-
- # Defines if the pattern set under pattern should be negated or not. Default is false.
- #negate: false
-
- # Match can be set to "after" or "before". It is used to define if lines should be append to a pattern
- # that was (not) matched before or after or as long as a pattern is not matched based on negate.
- # Note: After is the equivalent to previous and before is the equivalent to to next in Logstash
- #match: after
-
- # The maximum number of lines that are combined to one event.
- # In case there are more the max_lines the additional lines are discarded.
- # Default is 500
- #max_lines: 500
-
- # After the defined timeout, an multiline event is sent even if no new pattern was found to start a new event
- # Default is 5s.
- #timeout: 5s
-
- # 如果设置为trueFilebeat从文件尾开始监控文件新增内容把新增的每一行文件作为一个事件依次发送而不是从文件开始处重新发送所有内容。
- #tail_files: false
-
- # Filebeat检测到某个文件到了EOF之后每次等待多久再去检测文件是否有更新默认为1s。
- #backoff: 1s
-
- # Filebeat检测到某个文件到了EOF之后等待检测文件更新的最大时间默认是10秒。
- #max_backoff: 10s
-
- # 定义到达max_backoff的速度默认因子是2到达max_backoff后变成每次等待max_backoff那么长的时间才backoff一次直到文件有更新才会重置为backoff。
- #backoff_factor: 2
-
- # 这个选项关闭一个文件,当文件名称的变化。#该配置选项建议只在windows。
- #force_close_files: false
-
- # Additional prospector
- #-
- # Configuration to use stdin input
- #input_type: stdin
-
- # spooler的大小spooler中的事件数量超过这个阈值的时候会清空发送出去不论是否到达超时时间。
- #spool_size: 2048
-
- # 是否采用异步发送模式(实验!)
- #publish_async: false
-
- # spooler的超时时间如果到了超时时间spooler也会清空发送出去不论是否到达容量的阈值。
- #idle_timeout: 5s
-
- # 记录filebeat处理日志文件的位置的文件
- registry_file: /var/lib/filebeat/registry
-
- # 如果要在本配置文件中引入其他位置的配置文件可以写在这里需要写完整路径但是只处理prospector的部分。
- #config_dir:
-
-
-############################# Output ############
-
-# 输出到数据配置.单个实例数据可以输出到elasticsearch或者logstash选择其中一种注释掉另外一组输出配置。
-output:
-
- ### 输出数据到Elasticsearch
- elasticsearch:
- # IPv6 addresses should always be defined as: https://[2001:db8::1]:9200
- hosts: ["localhost:9200"]
-
- # 输出认证.
- #protocol: "https"
- #username: "admin"
- #password: "s3cr3t"
-
- # 启动进程数.
- #worker: 1
-
- # 输出数据到指定index default is "filebeat" 可以使用变量[filebeat-]YYYY.MM.DD keys.
- #index: "filebeat"
-
- # 一个模板用于设置在Elasticsearch映射默认模板加载是禁用的,没有加载模板这些设置可以调整或者覆盖现有的加载自己的模板
- #template:
-
- # Template name. default is filebeat.
- #name: "filebeat"
-
- # Path to template file
- #path: "filebeat.template.json"
-
- # Overwrite existing template
- #overwrite: false
-
- # Optional HTTP Path
- #path: "/elasticsearch"
-
- # Proxy server url
- #proxy_url: http://proxy:3128
-
- # 发送重试的次数取决于max_retries的设置默认为3
- #max_retries: 3
-
- # 单个elasticsearch批量API索引请求的最大事件数。默认是50。
- #bulk_max_size: 50
-
- # elasticsearch请求超时事件。默认90秒.
- #timeout: 90
-
- # 新事件两个批量API索引请求之间需要等待的秒数。如果bulk_max_size在该值之前到达额外的批量索引请求生效。
- #flush_interval: 1
-
- # elasticsearch是否保持拓扑。默认false。该值只支持Packetbeat。
- #save_topology: false
-
- # elasticsearch保存拓扑信息的有效时间。默认15秒。
- #topology_expire: 15
-
- # 配置TLS参数选项如证书颁发机构等用于基于https的连接。如果tls丢失主机的CAs用于https连接elasticsearch。
- #tls:
- # List of root certificates for HTTPS server verifications
- #certificate_authorities: ["/etc/pki/root/ca.pem"]
-
- # Certificate for TLS client authentication
- #certificate: "/etc/pki/client/cert.pem"
-
- # Client Certificate Key
- #certificate_key: "/etc/pki/client/cert.key"
-
- # Controls whether the client verifies server certificates and host name.
- # If insecure is set to true, all server host names and certificates will be
- # accepted. In this mode TLS based connections are susceptible to
- # man-in-the-middle attacks. Use only for testing.
- #insecure: true
-
- # Configure cipher suites to be used for TLS connections
- #cipher_suites: []
-
- # Configure curve types for ECDHE based cipher suites
- #curve_types: []
-
- # Configure minimum TLS version allowed for connection to logstash
- #min_version: 1.0
-
- # Configure maximum TLS version allowed for connection to logstash
- #max_version: 1.2
-
-
- ### 发送数据到logstash 单个实例数据可以输出到elasticsearch或者logstash选择其中一种注释掉另外一组输出配置。
- #logstash:
- # Logstash 主机地址
- #hosts: ["localhost:5044"]
-
- # 配置每个主机发布事件的worker数量。在负载均衡模式下最好启用。
- #worker: 1
-
- # #发送数据压缩级别
- #compression_level: 3
-
- # 如果设置为TRUE和配置了多台logstash主机输出插件将负载均衡的发布事件到所有logstash主机。
- #如果设置为false输出插件发送所有事件到随机的一台主机上如果选择的不可达将切换到另一台主机。默认是false。
- #loadbalance: true
-
- # 输出数据到指定index default is "filebeat" 可以使用变量[filebeat-]YYYY.MM.DD keys.
- #index: filebeat
-
- # Optional TLS. By default is off.
- #配置TLS参数选项如证书颁发机构等用于基于https的连接。如果tls丢失主机的CAs用于https连接elasticsearch。
- #tls:
- # List of root certificates for HTTPS server verifications
- #certificate_authorities: ["/etc/pki/root/ca.pem"]
-
- # Certificate for TLS client authentication
- #certificate: "/etc/pki/client/cert.pem"
-
- # Client Certificate Key
- #certificate_key: "/etc/pki/client/cert.key"
-
- # Controls whether the client verifies server certificates and host name.
- # If insecure is set to true, all server host names and certificates will be
- # accepted. In this mode TLS based connections are susceptible to
- # man-in-the-middle attacks. Use only for testing.
- #insecure: true
-
- # Configure cipher suites to be used for TLS connections
- #cipher_suites: []
-
- # Configure curve types for ECDHE based cipher suites
- #curve_types: []
-
-
- ### 文件输出将事务转存到一个文件每个事务是一个JSON格式。主要用于测试。也可以用作logstash输入。
- #file:
- # 指定文件保存的路径。
- #path: "/tmp/filebeat"
-
- # 文件名。默认是 Beat 名称。上面配置将生成 packetbeat, packetbeat.1, packetbeat.2 等文件。
- #filename: filebeat
-
- # 定义每个文件最大大小。当大小到达该值文件将轮滚。默认值是1000 KB
- #rotate_every_kb: 10000
-
- # 保留文件最大数量。文件数量到达该值将删除最旧的文件。默认是7一星期。
- #number_of_files: 7
-
-
- ### Console output 标准输出JSON 格式。
- # console:
- #如果设置为TRUE事件将很友好的格式化标准输出。默认false。
- #pretty: false
-
-
-############################# Shipper #############
-
-shipper:
- # #日志发送者信息标示
- # 如果没设置以hostname名自居。该名字包含在每个发布事务的shipper字段。可以以该名字对单个beat发送的所有事务分组。
- #name:
-
- # beat标签列表包含在每个发布事务的tags字段。标签可用很容易的按照不同的逻辑分组服务器。
- #例如一个web集群服务器可以对beat添加上webservers标签然后在kibana的visualisation界面以该标签过滤和查询整组服务器。
- #tags: ["service-X", "web-tier"]
-
- # 如果启用了ignore_outgoing选项beat将忽略从运行beat服务器上所有事务。
- #ignore_outgoing: true
-
- # 拓扑图刷新的间隔。也就是设置每个beat向拓扑图发布其IP地址的频率。默认是10秒。
- #refresh_topology_freq: 10
-
- # 拓扑的过期时间。在beat停止发布其IP地址时非常有用。当过期后IP地址将自动的从拓扑图中删除。默认是15秒。
- #topology_expire: 15
-
- # Internal queue size for single events in processing pipeline
- #queue_size: 1000
-
- # GeoIP数据库的搜索路径。beat找到GeoIP数据库后加载然后对每个事务输出client的GeoIP位置目前只有Packetbeat使用该选项。
- #geoip:
- #paths:
- # - "/usr/share/GeoIP/GeoLiteCity.dat"
- # - "/usr/local/var/GeoIP/GeoLiteCity.dat"
-
-
-############################# Logging #############
-
-
-# 配置beats日志。日志可以写入到syslog也可以是轮滚日志文件。默认是syslog。
-logging:
-
- # 如果启用发送所有日志到系统日志。
- #to_syslog: true
-
- # 日志发送到轮滚文件。
- #to_files: false
-
- #
- files:
- # 日志文件目录。
- #path: /var/log/mybeat
-
- # 日志文件名称
- #name: mybeat
-
- # 日志文件的最大大小。默认 10485760 (10 MB)。
- rotateeverybytes: 10485760 # = 10MB
-
- # 保留日志周期。 默认 7。值范围为2 到 1024。
- #keepfiles: 7
-
- # Enable debug output for selected components. To enable all selectors use ["*"]
- # Other available selectors are beat, publish, service
- # Multiple selectors can be chained.
- #selectors: [ ]
-
- # 日志级别。debug, info, warning, error 或 critical。如果使用debug但没有配置selectors* selectors将被使用。默认error。
- #level: error
-
-```
-
-#### 4.部署使用
-
-```
-vi /usr/local/logstash/conf.d/filebeat-client.conf
-input {
- kafka {
- type => "kafka-logs"
- bootstrap_servers => "172.17.0.4:9092,172.17.0.5:9092"
- group_id => "logstash"
- auto_offset_reset => "earliest"
- topics => "kafka_run_log"
- consumer_threads => 5
- decorate_events => true
- }
-}
-
-output {
- elasticsearch {
- index => 'kafka-run-log-%{+YYYY.MM.dd}'
- hosts => ["172.17.0.2:9200","172.17.0.3:9200"]
-}
-}
-
-4.在kafka中创建topic,跟logstash保持一致
-[root@xingdian conf.d]# bin/kafka-topics.sh --create --zookeeper 172.17.0.4:2181 --replication-factor 1 --partitions 1 --topic kafka_run_log
-查看topics
-[root@xingdian conf.d]# /usr/local/kafka_2.11-2.1.0/bin/kafka-topics.sh --zookeeper 172.17.0.4:2181 --list
-
-5.编写filebeat的配置文件filebeat.yml
-grep -Evn "^$|#" filebeat.yml (修改的内容,大致位置如下)
- 12:filebeat.prospectors:
- 18:- input_type: log
- 21: paths:
- 23: - /var/log/httpd/access_log 想要分析的日志文件
- 92:output.logstash:
- 94: hosts: ["10.0.0.72:8027"] logstash的主机和端口号 这里是输出给logstash
-与kafka的配置文件:
-21:- type: log
-24: enabled: true
-27: paths:
-28: - /var/log/yum.log
-146:output.kafka:
-147: enabled: true
-148: hosts: ["172.17.0.4:9092","172.17.0.5:9092"]
-149: topic: 'kafka_run_log'
-
-
-6.启动kafka服务器的logstash
-/usr/local/logstash/bin/logstash -f /usr/local/logstash/conf.d/filebeat-client.conf
-
-7.启动filebeat
-./filebeat -c filebeat.yml
-
-8.es集群访问查看
-
-9.kibana集群测试
-```
-
-## 七:Packetbeat
-
-```shell
-一、Packetbeat 概述
- Packetbeat 轻量型网络数据采集器,用于深挖网线上传输的数据,了解应用程序动态。Packetbeat 是一款轻量型网络数据包分析器,能够将数据发送至 Logstash 或 Elasticsearch等。
-
-目前,Packetbeat支持以下协议:
-• ICMP (v4 and v6)
-• DNS
-• HTTP
-• AMQP 0.9.1
-• Cassandra
-• Mysql
-• PostgreSQL
-• Redis
-• Thrift-RPC
-• MongoDB
-• Memcache
-• TLS
-二、Packetbeat 安装配置
-下载网址:https://www.elastic.co/downloads/beats
-1.下载部署安装
-4.logstash配置文件
-input {
- kafka {
- type => "packetbeat-logs"
- bootstrap_servers => "172.17.0.4:9092,172.17.0.5:9092"
- group_id => "packetbeat"
- auto_offset_reset => "earliest"
- topics => "packetbeat_log"
- consumer_threads => 5
- decorate_events => true
- }
-}
-
-output {
- elasticsearch {
- index => 'packetbeat-%{+YYYY.MM.dd}'
- hosts => ["172.17.0.2:9200","172.17.0.3:9200"]
-}
-}
-
-3.packetbeat配置文件
-172:output.kafka:
-173: enabled: true
-174: hosts: ["172.17.0.4:9092","172.17.0.5:9092"]
-175: topic: 'packetbeat_log'
-205:processors:
-206: - add_host_metadata: ~
-207: - add_cloud_metadata: ~
-
-4.启动
-先启动logstash再启动packetbeat
-
-5.访问nginx界面
-
-6.访问es界面查看
-
-7.访问kibana界面查看
-
-```
-
+
\ No newline at end of file
diff --git a/项目案例.md b/项目案例.md
new file mode 100644
index 0000000..536a7de
--- /dev/null
+++ b/项目案例.md
@@ -0,0 +1,126 @@
+项目案例
+
+作者:行癫(盗版必究)
+
+------
+
+#### 项目一
+
+ 某公司业务逻辑层Mysql数据库集群架构优化
+
+项目描述:
+
+ 根据公司业务需求需要对MySQL数据库进行主从复制实时备份,同时为了相应提升 MySQL数据库的读写性能, 决定采用 Mycat 中间件对 MySQL 数据库做读写分离。公司的数据库主库没有做高可用,如果数据库主库宕机那么会导致网站无法正常使用,从而影响业务和用户体验,最终决定使用MHA(mysql+keepalived)高可用方案来解决主库问题。
+
+责任描述:
+
+ 负责服务器的部署和环境初始化完成对服务的配置
+
+ 高可用集群构建
+
+ 集群环境测试,整理测试过程中的问题
+
+ 编写自动化脚本,撰写技术文档等
+
+#### 项目二
+
+ 某公司业务自动化上线
+
+项目描述:
+
+ 随着公司业务的发展,项目更新迭代逐渐频繁,测试及生产环境代码上线频繁,为了提高开发效率,决定搭建企业级自动化系统CI/CD;实现测试环境和生产环境的持续集成和持续交付
+
+项目职责:
+
+ 制定项目实施方案
+
+ 确定所需服务器的数量及配置
+
+ 进行系统优化及搭建基础环境
+
+ 构建CI/CD服务并进行配置
+
+ 测试自动化部署系统
+
+ 编写自动化脚本和技术文档
+
+#### 项目三
+
+ 架构升级构建日志分析系统EFK
+
+项目描述:
+
+ 随着公司规模不断扩大,业务日志数据不断增长,日志量大增、文本搜索缓慢、多维度查询,定位分析变得越来越困难,无法实时获取或展示业务的具体情况;为了更好的对日志进行分析和处理,公司决定上线EFK日F志分析系统;ELK是一套完整的日志收集、展示解决方案;通过Filebeat数据采集代理(Agent)将获取到的数据发给ES或者通过Logstash发给ES,然后进行后续的数据分析活动,用Kibana分析并展示。
+
+项目职责:
+
+ 参与系统的规划和实施,EFK简单、轻量、易扩展
+
+ 通过ELK可分布式的收集,检索以及完美的展示功能,解决集群运维中海量日志的收集,监控、预警和分析的问题
+
+ 测试服务的可用性,交付使用
+
+ 总结实施文档、项目实施和维护手册
+
+#### 项目四
+
+ 业务逻辑层架构升级Redis缓存服务器部署
+
+项目描述:
+
+ 由于业务逻辑层集群的数据访问量很多,直接访问后端Mysql服务器,导致数据库压力过大,访问速度很慢。为了缓解数据库的压力,加快访问速度。需要添加缓存服务器,对常用数据进行缓存,提高访问速度。而Redis支持的数据类型多,且支持数据持久化存储,是当前比较火的缓存服务器软件,所以决定采用Redis。
+
+项目职责:
+
+ 设计架构升级方案
+
+ 构建redis高可用架构
+
+ 集群可行性测试
+
+ 上线生产环境并入业务逻辑层
+
+ 编写自动化脚本及项目维护手册
+
+#### 项目五
+
+ 基于zabbix构建企业级监控平台
+
+项目描述:
+
+ 根据日常运维具体业务需求,完善公司运维体系,现需要对原有监控系统进行升级,实现部署zabbix监控系统平台;利用zabbix实现监控各种网络参数,保证服务器系统的安全运营,并提供灵活的通知机制以让系统管理员快速定位/解决存在的问题; 利用zabbix实现对远程服务器/网络状态的监视,数据收集等。
+
+项目职责:
+
+ 对现有监控进行总结,完善zabbix监控系统方案
+
+ 构建zabbix监控高可用平台
+
+ 规划监控指标,明确告警媒介
+
+ 规划通知策略,并编写项目文档
+
+#### 项目六
+
+ kubernetes云原生平台构建
+
+项目描述:
+
+ 随着公司的发展,使得业务逐渐的迁移Docker容器上,随着容器越来越多,为了更方便对应用进行管理,在非生产环境构建Kubernetes云原生集群,实现对Docker容器的管理,因设计到业务逻辑层业务调整,故需完成非生产环境的测试,确保业务逻辑层所有业务均可正常运行后,进行生产环境升级。
+
+项目职责:
+
+ 非生产环境构建kubernetes云原生集群
+
+ 生产环境迁移方案定制
+
+ 测试应用是否可在kubernetes集群运行
+
+ 编写项目文档和自动化运维脚本
+
+
+
+
+
+
+